Unity: Accelerating DNN Training Through Joint Optimization of Algebraic Transformations and Parallelization
Summary. The authors argue that DNN training optimizers must consider algebraic transformations and parallelization simultaneously for optimal performance. The authors build Unity on top of TASO, a prior work automatically synthesizing algebraic transformations in the forms of graph rewrites. Unity frames parallelization similarly as graph rewrites and thus enables automatic synthesis of parallelization strategies similar to TASO (more details below). Joint optimization enables up to 3.6x speedup with reasonable optimization time budget.
Discussion.
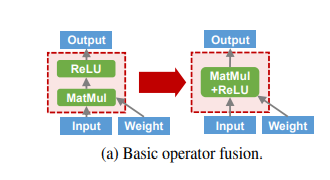
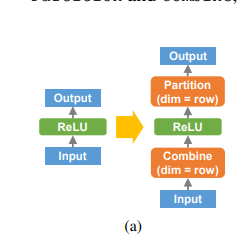
Optimization synthesis. As in TASO, the optimizer automatically synthesizes optimizations in the forms of graph rewrites (see left figure for an example of algebraic rewrite and right figure for an example of parallelization rewrite). To do this, Unity/TASO perform the following steps:
- Generate all subgraphs of a fixed size K,
- Run a set of random inputs through them to establish possible identities between pairs of subgraphs, based on whether outputs match on identical inputs.
- Based on a set of axioms, (e.g.∀x,y. add(x,y) = add(y, x)), they use Z3 to verify possible identities. In this step, verification failure for a single pair of subgraph may be due to two reasons: 1). the pair of subgraphs is not equivalent. 2). not enough axioms available to prove their identities. In the sencond case, human users may want to insert additional axioms.
In the end, the optimizers will generate a large repertoire of graph rewrites. Importantly, since smaller optimization steps can compose to form larger optimization steps, the restriction to consider only subgraphs below certain size K is not necessarily an issue.
Utility & evaluation. It is unclear whether Unity is helpful for LLMs in datacenter environments, where the models are sufficiently simple (transformers) that one may argue the optimal transformations are relatively obvious and the communication topologies are also reasonably simple. As we can see, Unity underperforms Megatron[2] on optimizing BERT-large.
We speculate that Unity will really shine in areas such as decentralized training or edge computing where there is peculiar and diverse constraints on computation and communication patterns, and where it is not economical to human engineer the best optimizations suitable for each model and hardware architecture.
Cost model. To make optimization runtime feasible, Unity must use a cost model to estimate the performance impact of optimization. The author claims to use cost model in line with [3], which estimates the runtime of a computation graph by summing all computation and communication time estimation. However, we wonder whether Unity may miss certain optimization opportunities as cost (especially communication cost) is in general not additive. For example, in [4], to estimate the communication cost associated with gradient exchange within a group of servers executing models using data parallelism, the slowest gradient exchange (i.e., max among all estimated gradient communication time) determines the cost of the entire group.
[1]: TASO: Optimizing Deep Learning Computation with Automatic Generation of Graph Substitutions
[2] Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
[3] Exploring Hidden Dimensions in Parallelizing Convolutional Neural Networks
[4] Decentralized Training of Foundation Models in Heterogeneous Environments