Flash Attention V2
Recap written by William Brandon
Key ideas
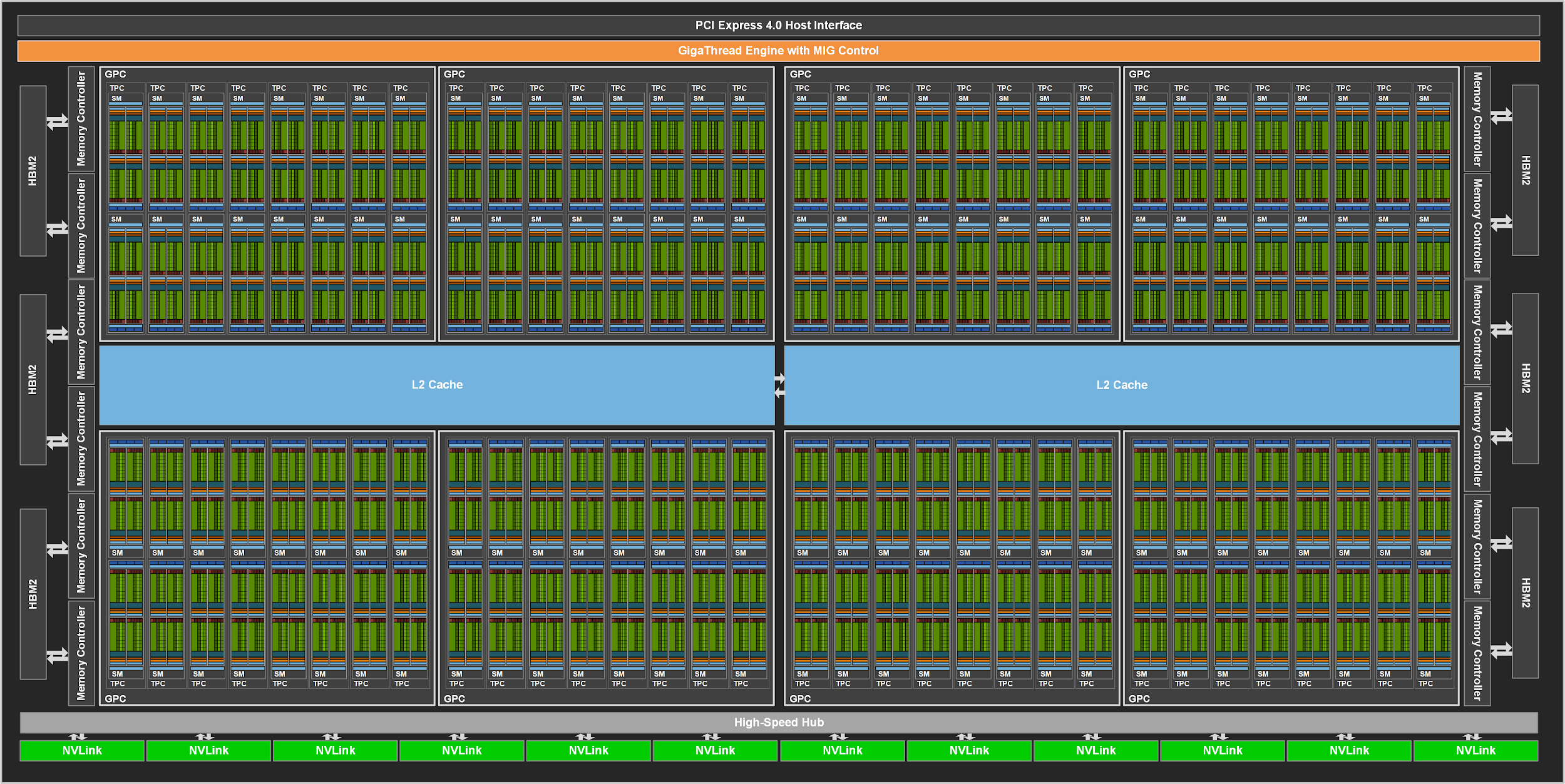
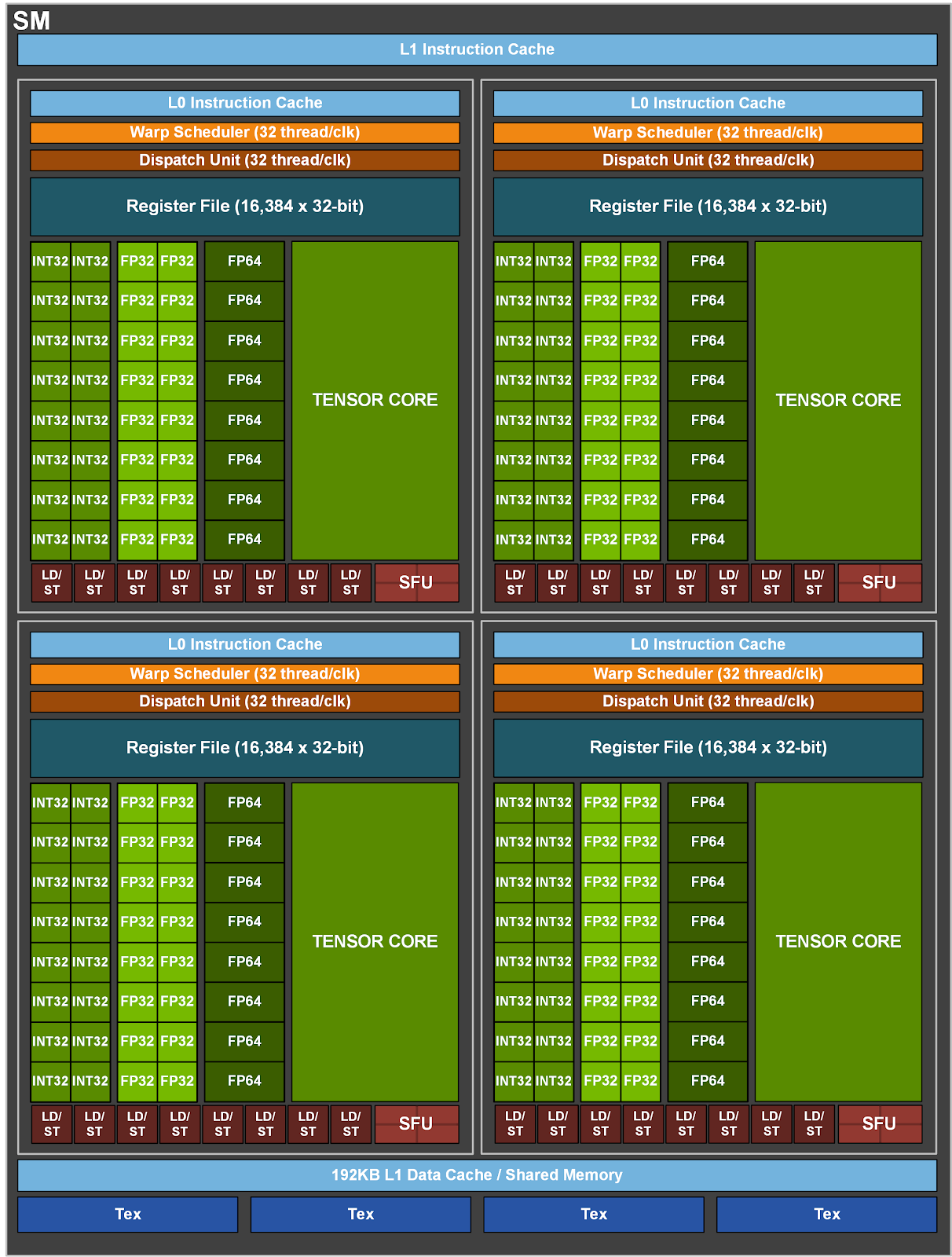
GPU compute hierarchy background
- An A100 GPU has 108 SMs, each SM has 4 warp schedulers, and each warp scheduler has many associated CUDA cores and tensor cores.
- The rough analogy to CPU hardware is:
| NVIDIA GPU concept | CPU concept |
| SM ("Streaming Multiprocessor") | Group of CPU cores sharing an L1 cache |
| Warp scheduler | Superscalar CPU core with hyperthreading |
| Warp | Thread executing 32-wide SIMD instructions |
| Thread | SIMD lane |
| CUDA core | ALU |
| Tensor core | Matrix accelerator unit |
- An A100 can sustain about 16x higher peak tensor FLOP/s than general-purpose FLOP/s, so it's important to minimize the number of non-tensor FLOP/s.
Schematic of a full GA100 GPU (which have more SMs than A100):
Schematic of a single Ampere SM:
Transformers background
- The core of attention is just computing
Softmax(Q K^T) Vwhere Q, K, and V are all relatively tall and skinny matrices (usually each matrix has around 1024 - 16384 rows, 64 - 128 columns)- In practice attention is usually batched in parallel across multiple sequences and multiple heads, but each head within each sequence presents an entirely independent sub-problem that we can consider in isolation.
- FlashAttention has a high arithmetic intensity and mostly performs tensor FLOPs, so in principle it should be possible to hit close to peak tensor FLOP/s utilization.
- However, the original FlashAttention 1 doesn't achieve this in practice, largely due to taking insufficient advantage of the massive parallelism available in the GPU compute hierarchy.
FlashAttention 2 innovations
- We can reduce the number of non-tensor FLOPs by reformulating how we implement some of the math for softmax.
- We can increase the amount of available parallelism by computing different row-chunks of the output matrix in parallel (i.e., parallelizing over the sequence dimension), even within a single head for a single sequence.
- We can reduce contention between warps within a single SM by having each warp compute a disjoint chunk of rows of the output matrix.
Questions
- Why does the FlashAttention 2 forward pass track and return the row-wise log-sum-exp
L? Does it play any role in the rest of the transformer forward pass, or only in the backward pass? Are downstream forward-pass kernels meant to consumeLfor any reason?
- Why does FlashAttention 2 only use 4 warps per threadblock? Is it not possible to achieve higher occupancies by using more warps?
- We know that an Ampere SM can only dispatch 4 warps per cycle, but it seems like using more than 4 warps would be ideal for latency hiding? Does the kernel make up for this by packing sufficient ILP into a single warp?
- Is the new parallelism over the sequence dimension in FlashAttention 2 implemented entirely at the level of threadblocks? Or is there any new within-threadblock sequence parallelism?
References
[1] FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness (Tri Dao et al., 2022)
[2] FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning (Tri Dao, 2023)
[3] https://developer.nvidia.com/blog/nvidia-ampere-architecture-in-depth/