DeepSeek V3 Tech Report
Q1: Why does rotary positional encoding only applies to half of query/key dimensions?
This is because rotary positional encoding is not compatible with multi-head latent attention, specifically the latent part. Here’s a more detailed explaination:
To begin with, for Multi-head Latent Attention:
- Key-value compression: A shared compressed representation
- Key decompression: The decompressed key is , where decoes the compressed representation
- Query computation:
- Attention score now becomes:
During inference, the attention score can be rewritten as:
where
This matrix absorption means there's no need to explicitly decompress the cached key vectors, significantly reducing memory usage and computation.
However, when we introduce Rotary Positional Embeddings (RoPE), complications arise:
- With standard RoPE application:
-
-
- The attention score becomes:
-
Since RoPE applies position-dependent rotations, the matrix absorption optimization () is no longer possible, as these rotations cannot be precomputed in a position-independent way.
To maintain both computational efficiency and positional awareness, the solution DeepSeek v3 adopts is to apply ROPE on only a subset of channels in the key vector, and leave the remaining channels uncompressed.
Q2: What is DualPipe, how do we interpret its illustration and relate it to its key performance characteristics?
- Another key technique that Deepseek V3 employs for training efficiency is “DualPipe”, as illustrated below. This is an intimidating graph, but let’s break it down into smaller pieces. Specifically, we will visually demonstrate three key performance characteristics of this DualPipe setup.
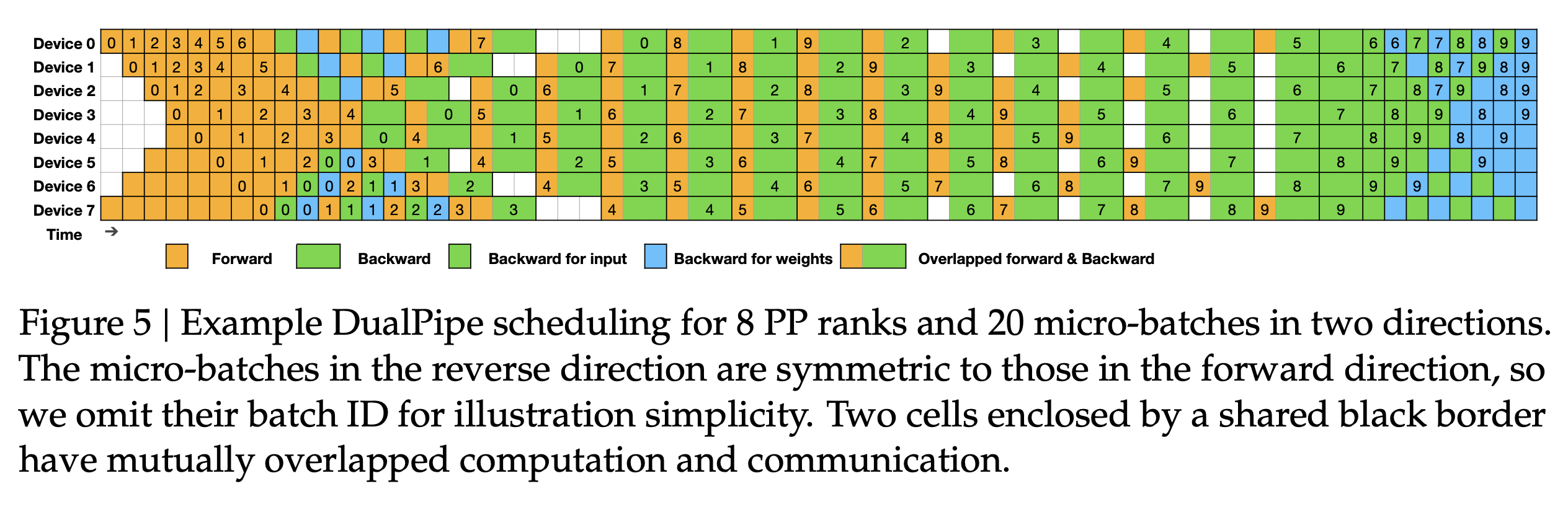
First off, the “Dual” part of DualPipe means that there’re two directions of pipeline happening simultaneously, as illustrated by the red and yellow arrows below. One key motivation for this is to reduce pipeline bubbles associated with pipeline warmup and cooldown.

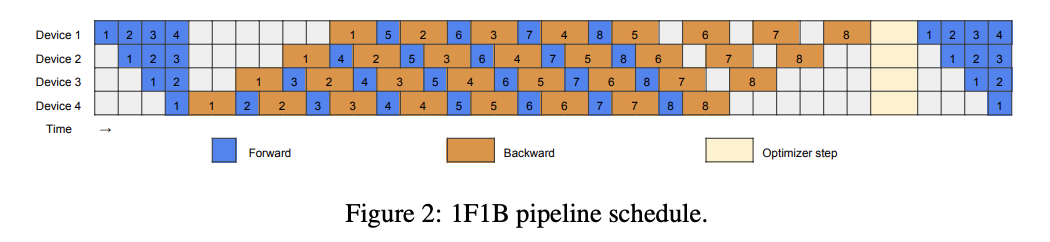
A naieve pipeline parallel strategy is 1F1B, illustrated below. Where the forward and backward pass of 8 microbatches are interleaved to reduce pipeline bubbles. Since synchronization is required between mini batches (as indicated by Optimizer step in the figure), this strategy leaves substantial bubble during pipeline warmup and cooldown, as shown by the idle timestamps in the begining/end. During these pipeline bubbles, workload is quite unevenly distributed; this motivates creating another pipeline in the opposite direction, utilizing the otherwise idle devices. Interleaving two pipelines should reduce pipeline bubbles approximately by a factor of 2.
However creating another pipeline direction comes with some cost. Firstly this means Device 0 will need to be in possession of both the first and last 1/PP ranks of the layers; similarly device 1 must have the next and 2nd to last 1/PP ranks of layers. As a result, each set of weights will exist in two copies.

Additionally, if we focus our attention on the first device only; i’ve annotated the number of microbatch activations this device must keep in its memory. We can see that because of the pipeline in the other direction, peak memory usage is 9 copies, which occured at the start of microbatch 7. Note that for 1F1B it’s always the number of PP ranks copy, in this case it is 8. So the 2nd direction of pipeline increases peak memory usage by 1 extra copy of microbatch activations.
Remark. Auxiliary loss free strategy for expert load balancing.
- In Mixture-of-Expert (MoE) models, it's common practice to distribute each expert across separate accelerators to efficiently manage memory constraints. DeepSeek V3 employs a gating mechanism to determine expert assignment for each token, using the formula: TopK(affinity_i + b_i), where affinity_i represents the predicted token-to-expert affinity for expert_i, and b_i is a bias term. For each token, the K experts with the highest combined scores (affinity plus bias) are activated, along with a subset of always-activated experts.
- A persistent challenge in MoE architectures is load imbalance, where certain experts are utilized significantly more than others. Rather than implementing the conventional auxiliary loss approach for load balancing, DeepSeek V3 introduces a new strategy: dynamically adjusting the bias terms (b_i) through small increments or decrements based on observed expert workload patterns. This adaptive bias adjustment maintains balanced expert utilization without requiring additional loss terms. Notably, ablation studies in Section 4.5.2 demonstrate the effectiveness of this approach compared to auxiliary loss-based methods, although detailed specifications of the baseline comparison are not fully documented.
- Furthermore, the specific magnitude of this increment is a hyper parameter, which functions just like learning rate. Thus it is possible that simply decoupling the learning rate for expert routing and weight learning is sufficient for reaping the benefits of auxiliary loss free load balancing.