Cramming: Training a Language Model on a Single GPU in One Day
Summary. The authors (Geiping et al.) tried a vast number of known tricks from prior works to improve masked language modeling (MLM) performance in the low compute-resource regime. Geiping et al. finds that while parameter count is the deciding factor for language modeling performance in the high compute resource regime, it remains the same in low compute resource regime. While the presentation makes it hard to discern which tricks are the most important, limited ablation study appears to show that the combination of Pre-Normalization layer and the aggressive learning rate schedule enabled by it contributes the most to improving model efficacy in the low compute-resource regime.
Discussion.
GLUE Performance. The following table in the paper shows that crammed BERT only suffer 2.6 points drop on GLUE performance. How should we interpret this? The answer seems elusive for 2 reasons. For one, arithmetic average is susceptible to outliers. Individual model performance on certain individual benchmarks (e.g., CoLA) can vary significantly to have an outsized effect on the final GLUE score. Thus it is unclear whether GLUE is a robust and accurate summary of model performance. For another, [1] and more recently [2] argue that the arithmetic average of normalized performance numbers are meaningless. Though the original argument of [1] does not directly apply in the case of GLUE benchmarks.

CoLA. The biggest performance drop from BERT-base to crammed BERT appears to come from CoLA benchmark. The task is to classify whether a sentence is grammatical. The reported metric is the Matthew's correlation coefficient between prediction and labels. 0 means no correlation and a value of 100% indicates perfect correlation. Why is crammed BERT significantly worse than BERT-base on CoLA? One hypothesis the author gives is the relative small dataset size (9.6K), which makes pre-training all the more important. Perhaps a better comparison between BERT-base and crammed BERT is to see how benchmark performance drops when finetuning dataset shrinks?
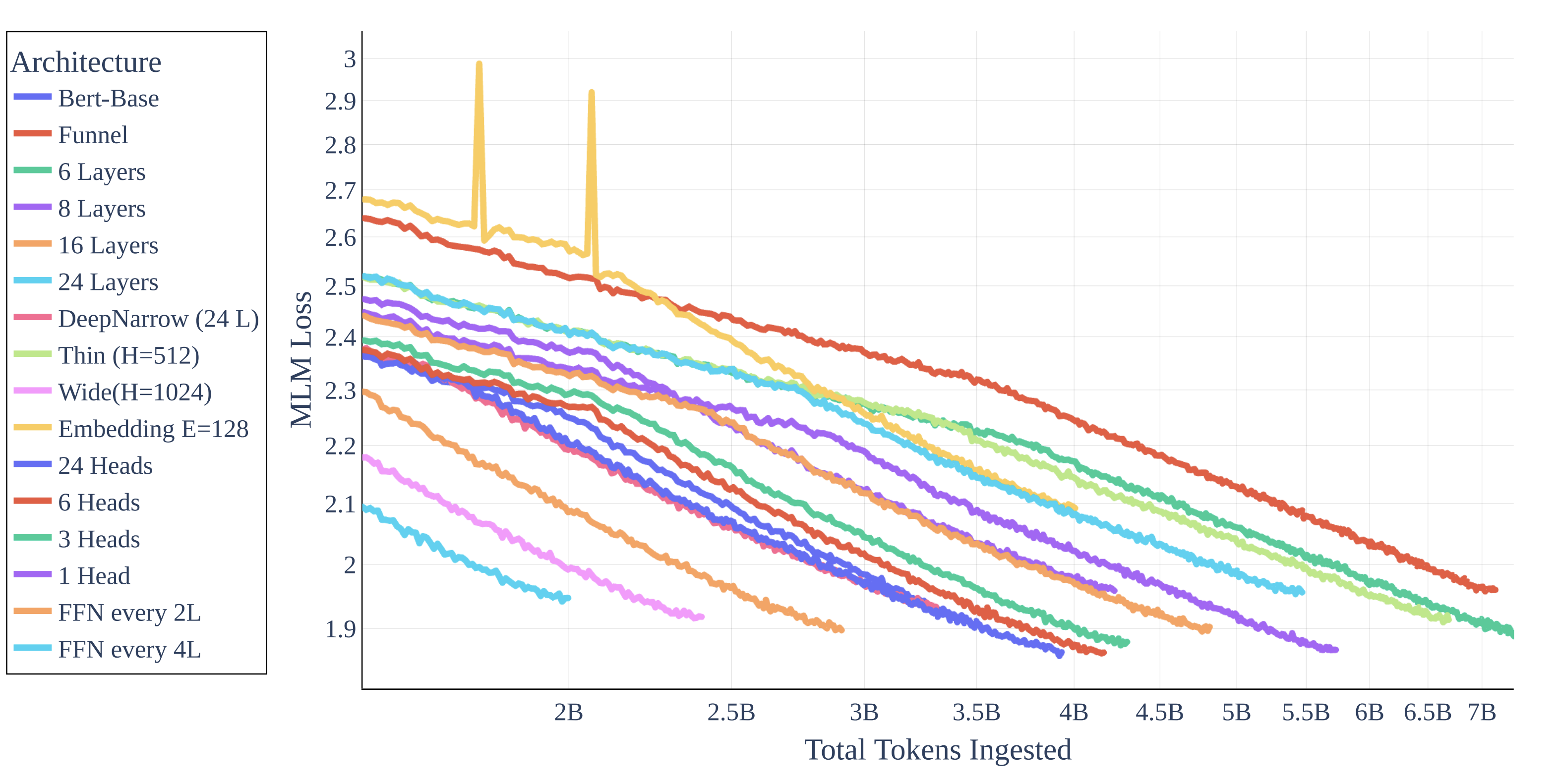
Parameter or FLOPS? A central observation from this paper is that it’s mostly parameter count that decides MLM performance. So architectural variations that keep parameter count the same contributes little to MLM loss at the end of training. However, some results may challenge this parameter-centric view of MLM performance. The following figure taken from the paper shows Funnel-Transformer as among the worst performing architecture modification in terms of final MLM loss. However Funnel-Transformer keeps parameter count constant while reducing the total amount of computations (FLOPS) by reducing the length of the intermediate hidden states, which is usually the same as the input across all layers. So perhaps the total FLOPs count correlates with MLM loss better than parameter count? Another datapoint to disentangle the effect of parameter v.s. FLOPS on MLM performance is ALBERT model, which employs cross-layer parameter sharing, effectively decreases parameter count without dropping FLOPs.
Scaling laws for vision models? We wonder why there’re no scaling laws for vision models, and hypothesize that signals in vision tasks are extremely high-dimensional and may therefore be much harder to extract than NLP signals. There’s also this blog post [3] that attributes the absence of CV scaling laws to training instabilities that prevents CV models from scaling up.
[1]: How Not to Lie with Statistics: The Correct Way to Summarize Benchmark Results
[2]: How not to Lie with a Benchmark: Rearranging NLP Leaderboards
[3]: Why Do We Have Huge Language Models and Small Vision Transformers? https://towardsdatascience.com/why-do-we-have-huge-language-models-and-small-vision-transformers-5d59ac36c1d6